Collection Configuration
The Collection configuration is where you can set up rules to follow while crawling or indexing the data sources. You can conduct a detailed configuration setup with the various sections available here.
You will have access to various technical parameters like indexing, concurrent request, download delay, the definition of allowed domains, specific field settings, and schedule the crawling frequency here.
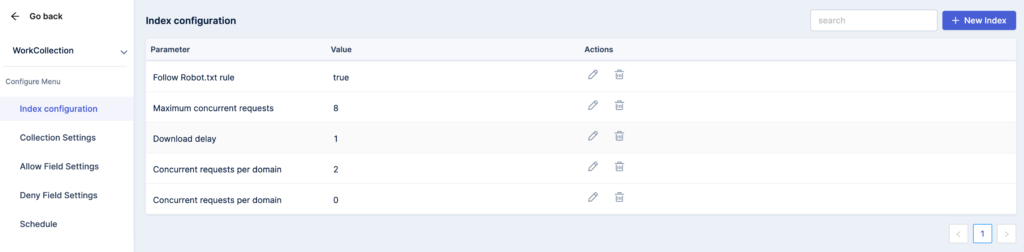
Index Configuration
- You can add a new index in the section by selecting parameters, assigning relevant values, and save your selection in the ‘New Index’ tab.
- There is also an option to edit, delete, and enter comments for the selected parameters. You can search for a specific index through the provided search bar.
You can choose from the specific list of parameters, including –
Follow Robot.txt file
Robots.txt is a text file created to instruct search engine robots to crawl pages on your website. You can enable or disable the robot.txt file for your collections.
Maximum concurrent requests
Keep a tab on the concurrent requests accepted by your search engine. When the limit is reached, new requests will be queued and executed based on arrival orders.
Download delay
Set a value for the delay in seconds before downloading consecutive documents on your website. This can act as a buffer to avoid the crawling speed from hitting the servers too hard.
Concurrent requests per domain
It will allow you to govern the number of concurrent requests that will be performed to any single domain.
Default request headers
The Headers property on the object returns a collection object that can be used to get or set the specific headers on a specific HTTP request.
Crawl depth limit
The maximum depth that will be allowed to crawl for any site. If zero, no limit will be imposed. For example, if the crawl depth of the homepage is 0, the URLs linked to the homepage will be 1 deep, and so on.
User-agent
You can direct the default user-agent that should be used while crawling when it is not subject to overriding. It will also prove useful when no overriding header is specified for requests.
Download Max Size
You can specify the maximum response size for the downloader to download. You can set the number to zero for disabling the same. The size is specified in bytes.
Collection Settings
When you wish to conduct changes for a particular collection by mass, the collection settings feature can help you alter/update the existing data sources by parameters here.
Let’s go over the parameters available in the Collection.

Allowed Domains
The options allow you to list the domains and give the spider or bot the permission to crawl the pages which are already added to the data source’s web pages.
The URL of the domain and subdomains that are not specified in the list will not be followed by the crawler.
Denied Domains
The option comes in handy when you explicitly want to instruct the crawler to not crawl specific web pages on your website. You can enter the URL that shouldn’t be crawled as the Value.
Allowed Content Type
If you wish to control the type of content that is being crawled, you can provide access by content type. You can choose different file types such as HTML, PDF, DOC, XLS, and more.
Denied Content to Crawl
Put a cap on certain types of content from being crawled by choosing this option. Any file in the website that holds these content types will not be crawled by the spider.
Field Selector
If you wish to map the fields by file type, you can add a new configuration, set the parameters as field selector, input values, choose the file type, and save the selection.

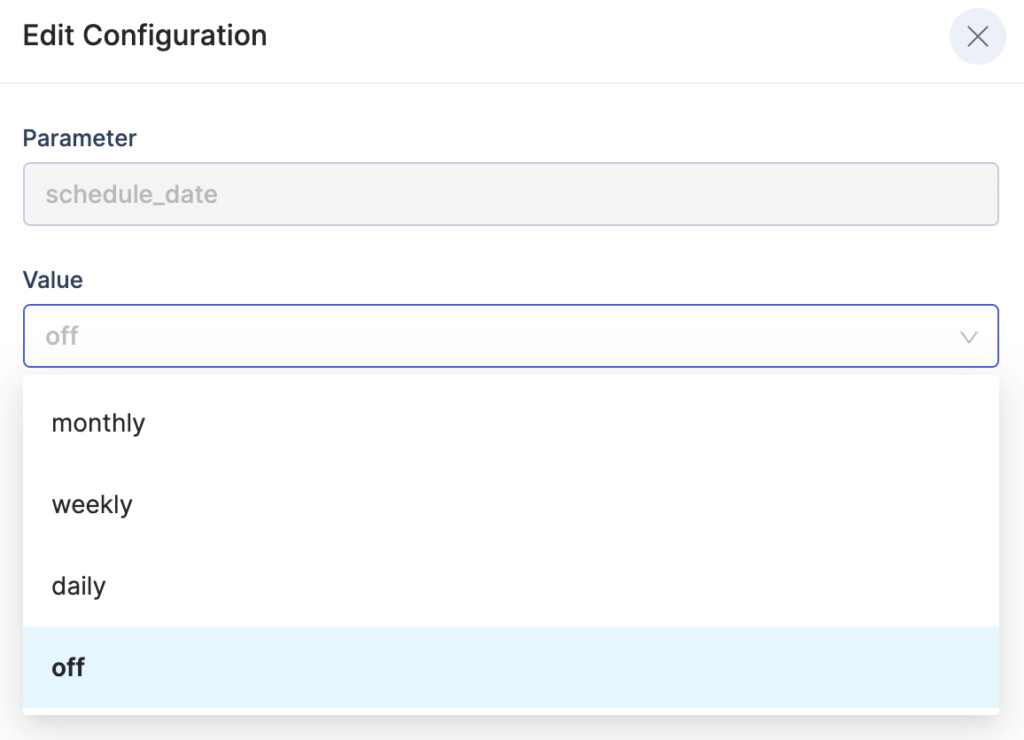
Schedule
You can set a definite crawling schedule for the collection by choosing the frequency of the crawling period – daily, weekly, or monthly, specific to your requirements. The default value is set based on the plan you chose.